MECD-Benchmark
MECD: Unlocking Multi-Event Causal Discovery in Video Reasoning
NeurIPS 2024 (Spotlight) + IEEE TPAMI 2025 </h2>
If you like our project, please give us a star ⭐ on GitHub for latest update. </h2>
[](https://arxiv.org/abs/2409.17647)
[](https://huggingface.co/datasets/tychen-sjtu/MECD)
[](https://arxiv.org/abs/2501.07227)
 ## 📰 News
[2024.09.26] 🔥🔥🔥 Our MECD is accepted in NeurIPS 2024 as a **Spotlight** Paper!
[2024.09.26] MECD dataset public available.
[2025.07.05] MECD+ dataset public available.
[2025.10.25] 🔥🔥🔥 Our MECD+ is accepted in IEEE TPAMI (IEEE Transactions on Pattern Analysis and Machine Intelligence) !
## 🏠 Overview
## 📰 News
[2024.09.26] 🔥🔥🔥 Our MECD is accepted in NeurIPS 2024 as a **Spotlight** Paper!
[2024.09.26] MECD dataset public available.
[2025.07.05] MECD+ dataset public available.
[2025.10.25] 🔥🔥🔥 Our MECD+ is accepted in IEEE TPAMI (IEEE Transactions on Pattern Analysis and Machine Intelligence) !
## 🏠 Overview
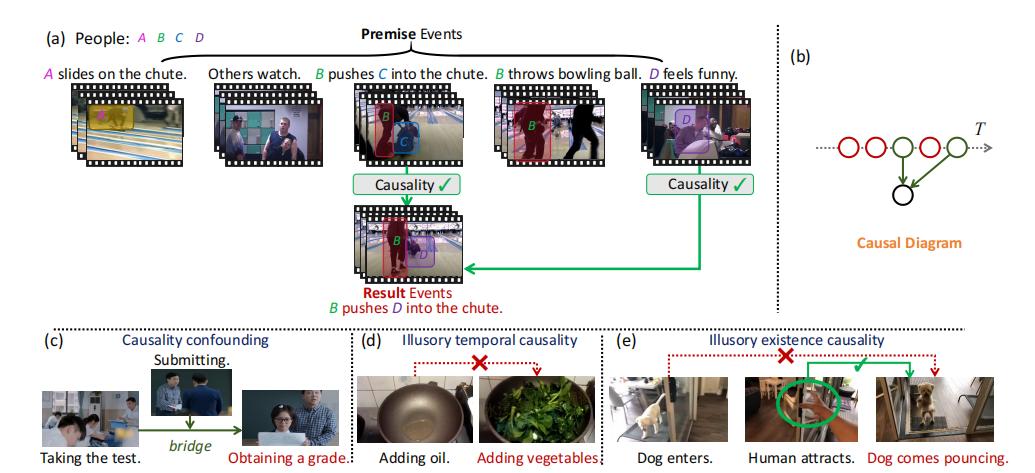 Video causal reasoning aims to achieve a high-level understanding of video content from a causal perspective.
However, current video reasoning tasks are limited in scope, primarily executed in a question-answering paradigm
and focusing on short videos containing only a single event and simple causal relations.
To fill this gap, we introduce a new task and dataset, Multi-Event Causal Discovery (MECD).
It aims to uncover the causal relations between events distributed chronologically across long videos.
To address MECD, we devise a novel framework inspired by the Granger Causality method,
using an efficient mask-based event prediction model to perform an Event Granger Test,
which estimates causality by comparing the predicted result event when premise events are masked versus unmasked.
Furthermore, we integrate causal inference techniques such as front-door adjustment and
counterfactual inference to address challenges in MECD like causality confounding and illusory causality.
An example of causality diagram:
Video causal reasoning aims to achieve a high-level understanding of video content from a causal perspective.
However, current video reasoning tasks are limited in scope, primarily executed in a question-answering paradigm
and focusing on short videos containing only a single event and simple causal relations.
To fill this gap, we introduce a new task and dataset, Multi-Event Causal Discovery (MECD).
It aims to uncover the causal relations between events distributed chronologically across long videos.
To address MECD, we devise a novel framework inspired by the Granger Causality method,
using an efficient mask-based event prediction model to perform an Event Granger Test,
which estimates causality by comparing the predicted result event when premise events are masked versus unmasked.
Furthermore, we integrate causal inference techniques such as front-door adjustment and
counterfactual inference to address challenges in MECD like causality confounding and illusory causality.
An example of causality diagram:
 ## 📊 MECD Dataset
Our MECD dataset includes 806 and 299 videos for training set and testing set, respectively.
## 📊 MECD Dataset
Our MECD dataset includes 806 and 299 videos for training set and testing set, respectively.
 ### 1. Annotation
#### 📄 Annotation Files
We provide JSON annotations for training, testing, and complete causal reasoning:
- **Training Set:** `captions/train.json`
- Includes the causal attribute: `relation`.
- **Test Set:** `captions/test.json`
- Includes the causal attribute: `relation`.
- **Full Causal Graph (Test):** `captions/test_complete.json`
- Introduces the additional attribute `all_relation`.
- Used for complete causal graph reasoning, evaluated by the **Average Structural Hamming Distance (Ave SHD)** metric.
#### 🔍 Visualization
You can preview the dataset and annotation display on [Hugging Face](https://huggingface.co/datasets/tychen-sjtu/MECD).
**Annotation Example:**
### 1. Annotation
#### 📄 Annotation Files
We provide JSON annotations for training, testing, and complete causal reasoning:
- **Training Set:** `captions/train.json`
- Includes the causal attribute: `relation`.
- **Test Set:** `captions/test.json`
- Includes the causal attribute: `relation`.
- **Full Causal Graph (Test):** `captions/test_complete.json`
- Introduces the additional attribute `all_relation`.
- Used for complete causal graph reasoning, evaluated by the **Average Structural Hamming Distance (Ave SHD)** metric.
#### 🔍 Visualization
You can preview the dataset and annotation display on [Hugging Face](https://huggingface.co/datasets/tychen-sjtu/MECD).
**Annotation Example:**
 ### 2. Video Data & Frames
#### 📥 Pre-extracted Frames (MECD)
For convenience, we provide **8-frame sampled results** for all videos in the MECD dataset. You can download them directly from Google Drive:
- **Training Set:** [Download Link](https://drive.google.com/file/d/1x-l8Ox9qTiE_ZNSMMnsLoAtnlotllImP/view?usp=drive_link)
- **Test Set:** [Download Link](https://drive.google.com/file/d/1h10MEKN_p1iDEhWZ8kbLraV38_1SeHvG/view?usp=drive_link)
#### 🎬 Raw Videos (ActivityNet)
The raw videos correspond to the official ActivityNet dataset. Please refer to the [ActivityNet Official Website](https://activity-net.org/) and use the provided Video IDs for retrieval.
**Download Resources:**
- 📝 **Request Form:** [Latest Download Request Form](https://docs.google.com/forms/d/e/1FAIpQLSdxhNVeeSCwB2USAfeNWCaI9saVT6i2hpiiizVYfa3MsTyamg/viewform)
- 🐛 **Troubleshooting:** For download issues, refer to [ActivityNet Issue #103](https://github.com/activitynet/ActivityNet/issues/103).
> **Missing Data Support:**
> If you encounter missing videos in your current ActivityNet download, please email the specific `Video_ID` to [tieyuanchen@sjtu.edu.cn](mailto:tieyuanchen@sjtu.edu.cn), and we will assist you.
The pretraining feature extracted by ResNet200 can be got by following the command below (details can be found in [VAR](https://github.com/leonnnop/VAR)) :
```bash
python feature_kit/extract_feature.py
```
### 3. Update
- **[2025.07.05]** 🔥 **Update:** Our extension work **"MECD+: Unlocking Event-Level Causal Graph Discovery for Video Reasoning"** has been accepted by **IEEE TPAMI**!
[](https://arxiv.org/abs/2501.07227)
- **[2025.07.05]** ➕ **MECD+ Data Release:**
- The newly introduced training data is available in `captions/train_mecd_plus.json`.
- Corresponding Video IDs and original sources can be found in the [Eventbench Dataset](https://huggingface.co/datasets/RUCAIBox/Event-Bench).
## 🗝️ Training & Validating
For training and our validating VGCM(Video Granger Causality Model), please follow the command below:
```bash
sh scripts/train.sh
```
#### 🚀 Benchmark Results
### 2. Video Data & Frames
#### 📥 Pre-extracted Frames (MECD)
For convenience, we provide **8-frame sampled results** for all videos in the MECD dataset. You can download them directly from Google Drive:
- **Training Set:** [Download Link](https://drive.google.com/file/d/1x-l8Ox9qTiE_ZNSMMnsLoAtnlotllImP/view?usp=drive_link)
- **Test Set:** [Download Link](https://drive.google.com/file/d/1h10MEKN_p1iDEhWZ8kbLraV38_1SeHvG/view?usp=drive_link)
#### 🎬 Raw Videos (ActivityNet)
The raw videos correspond to the official ActivityNet dataset. Please refer to the [ActivityNet Official Website](https://activity-net.org/) and use the provided Video IDs for retrieval.
**Download Resources:**
- 📝 **Request Form:** [Latest Download Request Form](https://docs.google.com/forms/d/e/1FAIpQLSdxhNVeeSCwB2USAfeNWCaI9saVT6i2hpiiizVYfa3MsTyamg/viewform)
- 🐛 **Troubleshooting:** For download issues, refer to [ActivityNet Issue #103](https://github.com/activitynet/ActivityNet/issues/103).
> **Missing Data Support:**
> If you encounter missing videos in your current ActivityNet download, please email the specific `Video_ID` to [tieyuanchen@sjtu.edu.cn](mailto:tieyuanchen@sjtu.edu.cn), and we will assist you.
The pretraining feature extracted by ResNet200 can be got by following the command below (details can be found in [VAR](https://github.com/leonnnop/VAR)) :
```bash
python feature_kit/extract_feature.py
```
### 3. Update
- **[2025.07.05]** 🔥 **Update:** Our extension work **"MECD+: Unlocking Event-Level Causal Graph Discovery for Video Reasoning"** has been accepted by **IEEE TPAMI**!
[](https://arxiv.org/abs/2501.07227)
- **[2025.07.05]** ➕ **MECD+ Data Release:**
- The newly introduced training data is available in `captions/train_mecd_plus.json`.
- Corresponding Video IDs and original sources can be found in the [Eventbench Dataset](https://huggingface.co/datasets/RUCAIBox/Event-Bench).
## 🗝️ Training & Validating
For training and our validating VGCM(Video Granger Causality Model), please follow the command below:
```bash
sh scripts/train.sh
```
#### 🚀 Benchmark Results
 #### 📃 Hyperparameters settings
To reproduce our results in the above table, please follow the default hyperparameters settings in: `src/runner.py` and `scripts/train.sh`
## 🔥 Fine-tuning & Evaluation of VLLMs
We fine-tune the vision-language projector of 🦙Video-LLaVA and 🦜VideoChat2 using LoRA under its official implementation on our entire MECD training set.
During the fine-tuning phase, the relation is transformed into a list of length (n-1), and the regular pattern of causality representation offered by the conversation is supplied to the VLLM.
Task prompt can be found in (`mecd_vllm_finetune/Video-LLaVA-ft/videollava/conversation.py` and `mecd_vllm_finetune/VideoChat2-ft/multi_event.py`) :
```bash
system = "Task: The video consists of n events,
and the text description of each event has been given correspondingly(separated by " ",).
You need to judge whether the former events in the video are the cause of the last event or not,
the probability of the cause 0(non-causal) or 1(causal) is expressed as the output, "
```
Please follow the command to reproduce thr fine-tuning result on our MECD benchmark:
Evaluate the causal discovery ability after fine-tuning of 🦙Video-LLaVA:
```bash
cd mecd_vllm_finetune/Video-LLaVA-ft
sh scripts/v1_5/finetune_lora.sh
python videollava/eval/video/run_inference_causal_inference.py
```
Evaluate the causal discovery ability after fine-tuning of 🦜VideoChat2:
```bash
cd mecd_vllm_fewshot/VideoChat2-ft
OMP_NUM_THREADS=2 torchrun --nnodes=1 --nproc_per_node=8 tasks/train_it.py ./scripts/videochat_mistral/config_7b_stage3.py
python multi_event.py
```
## ❄️ Few-shot (In-Context Learning) Evaluation of LLMs &VLLMs
All LLM-based and VLLM-based models are evaluated under a few-shot setting (In-Context Learning).
Specifically, following the approach in causal discovery for NLP tasks and after proving the sufficiency,
three representative examples are provided during inference, which can be found in `mecd_llm_fewshot/prompt.txt`, `mecd_vllm_fewshot/video_chat2/multi_event.py`,
and `mecd_vllm_fewshot/Video-LLaVA/videollava/conversation.py`.
#### 🦙Video-LLaVA
Please follow the command to evaluate the In-Context causal discovery ability of Video-LLaVA:
```bash
cd mecd_vllm_fewshot/Video-LLaVA
python videollava/eval/video/run_inference_causal_inference.py
```
#### 🦜Videochat2
Similarly, please follow the command to evaluate the In-Context causal discovery ability of Videochat2:
```bash
cd mecd_vllm_fewshot/VideoChat2
python multi_event.py
```
#### GPT-4
Similarly, please follow the command to evaluate the In-Context causal discovery ability of GPT-4:
```bash
cd mecd_llm_fewshot
python gpt4.py
```
#### Gemini-pro
Similarly, please follow the command to evaluate the In-Context causal discovery ability of Gemini-pro:
```bash
cd mecd_llm_fewshot
python gemini.py
```
## Video Question Answering Enhancement
Additional causal relations facilitates VLLM with stronger VideoQA ability.
527 examples overlap between our MECD dataset and the ActivityNet-QA dataset: `question_answering/QA.json`.
No additional training process is needed.
The example of facilitating VideoChat2 QA process:
```bash
cd mecd_vllm_fewshot/VideoChat2-ft
python run_qa_causal_mistral.py
```
## 🛠️ Requirements and Installation
First, you will need to set up the environment and extract pretraining weight of each video.
We offer an environment suitable for both VGCM and all VLLMs:
```bash
conda create -n mecd python=3.10
conda activate mecd
pip install -r requirements.txt
```
The pre-training weight of VGCM is available in [Google Drive](https://drive.google.com/file/d/1FScQim-nPgpr-SYRPIzVd5Dg6YYJbwQ1/view?usp=sharing).
## ✏️ Citation
```bash
@article{chen2024mecd,
title={MECD: Unlocking multi-event causal discovery in video reasoning},
author={Chen, Tieyuan and Liu, Huabin and He, Tianyao and Chen, Yihang and Ma, Xiao and Zhong, Cheng and Zhang, Yang and Wang, Yingxue and Lin, Hui and Lin, Weiyao and others},
journal={Advances in Neural Information Processing Systems},
volume={37},
pages={92554--92580},
year={2024}
}
@article{chen2025mecd+,
title={MECD+: Unlocking Event-Level Causal Graph Discovery for Video Reasoning},
author={Chen, Tieyuan and Liu, Huabin and Wang, Yi and Chen, Yihang and He, Tianyao and Gan, Chaofan and He, Huanyu and Lin, Weiyao},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year={2025}
}
```
### 👍 Acknowledgement
We would also like to recognize and commend the following open source projects, thank you for your great contribution to the open source community:
[VAR](https://github.com/leonnnop/VAR), [Video-LLaVA](https://github.com/PKU-YuanGroup/Video-LLaVA), [VideoChat2](https://github.com/OpenGVLab/Ask-Anything)
We would like to express our sincere gratitude to the PCs, SACs, ACs, as well as Reviewers 17Ce, 2Vef, eXFX, and 9my4, for their constructive feedback and support provided during the review process of NeurIPS 2024. Their insightful comments have been instrumental in enhancing the quality of our work.
We would also like to express our sincere gratitude to the TPAMI Associate Editor of MECD+, Reviewer 1-3 of MECD+, for their constructive suggestions and recognition during the review process of MECD+.
### ⏳ Ongoing
We will continue to update the performance of new state-of-the-art (SOTA) models on the MECD (MECD+) dataset,
and we will also continuously expand the volume of data and video sources in MECD (MECD+).
#### 📃 Hyperparameters settings
To reproduce our results in the above table, please follow the default hyperparameters settings in: `src/runner.py` and `scripts/train.sh`
## 🔥 Fine-tuning & Evaluation of VLLMs
We fine-tune the vision-language projector of 🦙Video-LLaVA and 🦜VideoChat2 using LoRA under its official implementation on our entire MECD training set.
During the fine-tuning phase, the relation is transformed into a list of length (n-1), and the regular pattern of causality representation offered by the conversation is supplied to the VLLM.
Task prompt can be found in (`mecd_vllm_finetune/Video-LLaVA-ft/videollava/conversation.py` and `mecd_vllm_finetune/VideoChat2-ft/multi_event.py`) :
```bash
system = "Task: The video consists of n events,
and the text description of each event has been given correspondingly(separated by " ",).
You need to judge whether the former events in the video are the cause of the last event or not,
the probability of the cause 0(non-causal) or 1(causal) is expressed as the output, "
```
Please follow the command to reproduce thr fine-tuning result on our MECD benchmark:
Evaluate the causal discovery ability after fine-tuning of 🦙Video-LLaVA:
```bash
cd mecd_vllm_finetune/Video-LLaVA-ft
sh scripts/v1_5/finetune_lora.sh
python videollava/eval/video/run_inference_causal_inference.py
```
Evaluate the causal discovery ability after fine-tuning of 🦜VideoChat2:
```bash
cd mecd_vllm_fewshot/VideoChat2-ft
OMP_NUM_THREADS=2 torchrun --nnodes=1 --nproc_per_node=8 tasks/train_it.py ./scripts/videochat_mistral/config_7b_stage3.py
python multi_event.py
```
## ❄️ Few-shot (In-Context Learning) Evaluation of LLMs &VLLMs
All LLM-based and VLLM-based models are evaluated under a few-shot setting (In-Context Learning).
Specifically, following the approach in causal discovery for NLP tasks and after proving the sufficiency,
three representative examples are provided during inference, which can be found in `mecd_llm_fewshot/prompt.txt`, `mecd_vllm_fewshot/video_chat2/multi_event.py`,
and `mecd_vllm_fewshot/Video-LLaVA/videollava/conversation.py`.
#### 🦙Video-LLaVA
Please follow the command to evaluate the In-Context causal discovery ability of Video-LLaVA:
```bash
cd mecd_vllm_fewshot/Video-LLaVA
python videollava/eval/video/run_inference_causal_inference.py
```
#### 🦜Videochat2
Similarly, please follow the command to evaluate the In-Context causal discovery ability of Videochat2:
```bash
cd mecd_vllm_fewshot/VideoChat2
python multi_event.py
```
#### GPT-4
Similarly, please follow the command to evaluate the In-Context causal discovery ability of GPT-4:
```bash
cd mecd_llm_fewshot
python gpt4.py
```
#### Gemini-pro
Similarly, please follow the command to evaluate the In-Context causal discovery ability of Gemini-pro:
```bash
cd mecd_llm_fewshot
python gemini.py
```
## Video Question Answering Enhancement
Additional causal relations facilitates VLLM with stronger VideoQA ability.
527 examples overlap between our MECD dataset and the ActivityNet-QA dataset: `question_answering/QA.json`.
No additional training process is needed.
The example of facilitating VideoChat2 QA process:
```bash
cd mecd_vllm_fewshot/VideoChat2-ft
python run_qa_causal_mistral.py
```
## 🛠️ Requirements and Installation
First, you will need to set up the environment and extract pretraining weight of each video.
We offer an environment suitable for both VGCM and all VLLMs:
```bash
conda create -n mecd python=3.10
conda activate mecd
pip install -r requirements.txt
```
The pre-training weight of VGCM is available in [Google Drive](https://drive.google.com/file/d/1FScQim-nPgpr-SYRPIzVd5Dg6YYJbwQ1/view?usp=sharing).
## ✏️ Citation
```bash
@article{chen2024mecd,
title={MECD: Unlocking multi-event causal discovery in video reasoning},
author={Chen, Tieyuan and Liu, Huabin and He, Tianyao and Chen, Yihang and Ma, Xiao and Zhong, Cheng and Zhang, Yang and Wang, Yingxue and Lin, Hui and Lin, Weiyao and others},
journal={Advances in Neural Information Processing Systems},
volume={37},
pages={92554--92580},
year={2024}
}
@article{chen2025mecd+,
title={MECD+: Unlocking Event-Level Causal Graph Discovery for Video Reasoning},
author={Chen, Tieyuan and Liu, Huabin and Wang, Yi and Chen, Yihang and He, Tianyao and Gan, Chaofan and He, Huanyu and Lin, Weiyao},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year={2025}
}
```
### 👍 Acknowledgement
We would also like to recognize and commend the following open source projects, thank you for your great contribution to the open source community:
[VAR](https://github.com/leonnnop/VAR), [Video-LLaVA](https://github.com/PKU-YuanGroup/Video-LLaVA), [VideoChat2](https://github.com/OpenGVLab/Ask-Anything)
We would like to express our sincere gratitude to the PCs, SACs, ACs, as well as Reviewers 17Ce, 2Vef, eXFX, and 9my4, for their constructive feedback and support provided during the review process of NeurIPS 2024. Their insightful comments have been instrumental in enhancing the quality of our work.
We would also like to express our sincere gratitude to the TPAMI Associate Editor of MECD+, Reviewer 1-3 of MECD+, for their constructive suggestions and recognition during the review process of MECD+.
### ⏳ Ongoing
We will continue to update the performance of new state-of-the-art (SOTA) models on the MECD (MECD+) dataset,
and we will also continuously expand the volume of data and video sources in MECD (MECD+).
## 📰 News
[2024.09.26] 🔥🔥🔥 Our MECD is accepted in NeurIPS 2024 as a **Spotlight** Paper!
[2024.09.26] MECD dataset public available.
[2025.07.05] MECD+ dataset public available.
[2025.10.25] 🔥🔥🔥 Our MECD+ is accepted in IEEE TPAMI (IEEE Transactions on Pattern Analysis and Machine Intelligence) !
## 🏠 Overview
Video causal reasoning aims to achieve a high-level understanding of video content from a causal perspective.
However, current video reasoning tasks are limited in scope, primarily executed in a question-answering paradigm
and focusing on short videos containing only a single event and simple causal relations.
To fill this gap, we introduce a new task and dataset, Multi-Event Causal Discovery (MECD).
It aims to uncover the causal relations between events distributed chronologically across long videos.
To address MECD, we devise a novel framework inspired by the Granger Causality method,
using an efficient mask-based event prediction model to perform an Event Granger Test,
which estimates causality by comparing the predicted result event when premise events are masked versus unmasked.
Furthermore, we integrate causal inference techniques such as front-door adjustment and
counterfactual inference to address challenges in MECD like causality confounding and illusory causality.
An example of causality diagram:
## 📊 MECD Dataset
Our MECD dataset includes 806 and 299 videos for training set and testing set, respectively.
### 1. Annotation
#### 📄 Annotation Files
We provide JSON annotations for training, testing, and complete causal reasoning:
- **Training Set:** `captions/train.json`
- Includes the causal attribute: `relation`.
- **Test Set:** `captions/test.json`
- Includes the causal attribute: `relation`.
- **Full Causal Graph (Test):** `captions/test_complete.json`
- Introduces the additional attribute `all_relation`.
- Used for complete causal graph reasoning, evaluated by the **Average Structural Hamming Distance (Ave SHD)** metric.
#### 🔍 Visualization
You can preview the dataset and annotation display on [Hugging Face](https://huggingface.co/datasets/tychen-sjtu/MECD).
**Annotation Example:**
### 2. Video Data & Frames
#### 📥 Pre-extracted Frames (MECD)
For convenience, we provide **8-frame sampled results** for all videos in the MECD dataset. You can download them directly from Google Drive:
- **Training Set:** [Download Link](https://drive.google.com/file/d/1x-l8Ox9qTiE_ZNSMMnsLoAtnlotllImP/view?usp=drive_link)
- **Test Set:** [Download Link](https://drive.google.com/file/d/1h10MEKN_p1iDEhWZ8kbLraV38_1SeHvG/view?usp=drive_link)
#### 🎬 Raw Videos (ActivityNet)
The raw videos correspond to the official ActivityNet dataset. Please refer to the [ActivityNet Official Website](https://activity-net.org/) and use the provided Video IDs for retrieval.
**Download Resources:**
- 📝 **Request Form:** [Latest Download Request Form](https://docs.google.com/forms/d/e/1FAIpQLSdxhNVeeSCwB2USAfeNWCaI9saVT6i2hpiiizVYfa3MsTyamg/viewform)
- 🐛 **Troubleshooting:** For download issues, refer to [ActivityNet Issue #103](https://github.com/activitynet/ActivityNet/issues/103).
> **Missing Data Support:**
> If you encounter missing videos in your current ActivityNet download, please email the specific `Video_ID` to [tieyuanchen@sjtu.edu.cn](mailto:tieyuanchen@sjtu.edu.cn), and we will assist you.
The pretraining feature extracted by ResNet200 can be got by following the command below (details can be found in [VAR](https://github.com/leonnnop/VAR)) :
```bash
python feature_kit/extract_feature.py
```
### 3. Update
- **[2025.07.05]** 🔥 **Update:** Our extension work **"MECD+: Unlocking Event-Level Causal Graph Discovery for Video Reasoning"** has been accepted by **IEEE TPAMI**!
[](https://arxiv.org/abs/2501.07227)
- **[2025.07.05]** ➕ **MECD+ Data Release:**
- The newly introduced training data is available in `captions/train_mecd_plus.json`.
- Corresponding Video IDs and original sources can be found in the [Eventbench Dataset](https://huggingface.co/datasets/RUCAIBox/Event-Bench).
## 🗝️ Training & Validating
For training and our validating VGCM(Video Granger Causality Model), please follow the command below:
```bash
sh scripts/train.sh
```
#### 🚀 Benchmark Results
#### 📃 Hyperparameters settings
To reproduce our results in the above table, please follow the default hyperparameters settings in: `src/runner.py` and `scripts/train.sh`
## 🔥 Fine-tuning & Evaluation of VLLMs
We fine-tune the vision-language projector of 🦙Video-LLaVA and 🦜VideoChat2 using LoRA under its official implementation on our entire MECD training set.
During the fine-tuning phase, the relation is transformed into a list of length (n-1), and the regular pattern of causality representation offered by the conversation is supplied to the VLLM.
Task prompt can be found in (`mecd_vllm_finetune/Video-LLaVA-ft/videollava/conversation.py` and `mecd_vllm_finetune/VideoChat2-ft/multi_event.py`) :
```bash
system = "Task: The video consists of n events,
and the text description of each event has been given correspondingly(separated by " ",).
You need to judge whether the former events in the video are the cause of the last event or not,
the probability of the cause 0(non-causal) or 1(causal) is expressed as the output, "
```
Please follow the command to reproduce thr fine-tuning result on our MECD benchmark:
Evaluate the causal discovery ability after fine-tuning of 🦙Video-LLaVA:
```bash
cd mecd_vllm_finetune/Video-LLaVA-ft
sh scripts/v1_5/finetune_lora.sh
python videollava/eval/video/run_inference_causal_inference.py
```
Evaluate the causal discovery ability after fine-tuning of 🦜VideoChat2:
```bash
cd mecd_vllm_fewshot/VideoChat2-ft
OMP_NUM_THREADS=2 torchrun --nnodes=1 --nproc_per_node=8 tasks/train_it.py ./scripts/videochat_mistral/config_7b_stage3.py
python multi_event.py
```
## ❄️ Few-shot (In-Context Learning) Evaluation of LLMs &VLLMs
All LLM-based and VLLM-based models are evaluated under a few-shot setting (In-Context Learning).
Specifically, following the approach in causal discovery for NLP tasks and after proving the sufficiency,
three representative examples are provided during inference, which can be found in `mecd_llm_fewshot/prompt.txt`, `mecd_vllm_fewshot/video_chat2/multi_event.py`,
and `mecd_vllm_fewshot/Video-LLaVA/videollava/conversation.py`.
#### 🦙Video-LLaVA
Please follow the command to evaluate the In-Context causal discovery ability of Video-LLaVA:
```bash
cd mecd_vllm_fewshot/Video-LLaVA
python videollava/eval/video/run_inference_causal_inference.py
```
#### 🦜Videochat2
Similarly, please follow the command to evaluate the In-Context causal discovery ability of Videochat2:
```bash
cd mecd_vllm_fewshot/VideoChat2
python multi_event.py
```
#### GPT-4
Similarly, please follow the command to evaluate the In-Context causal discovery ability of GPT-4:
```bash
cd mecd_llm_fewshot
python gpt4.py
```
#### Gemini-pro
Similarly, please follow the command to evaluate the In-Context causal discovery ability of Gemini-pro:
```bash
cd mecd_llm_fewshot
python gemini.py
```
## Video Question Answering Enhancement
Additional causal relations facilitates VLLM with stronger VideoQA ability.
527 examples overlap between our MECD dataset and the ActivityNet-QA dataset: `question_answering/QA.json`.
No additional training process is needed.
The example of facilitating VideoChat2 QA process:
```bash
cd mecd_vllm_fewshot/VideoChat2-ft
python run_qa_causal_mistral.py
```
## 🛠️ Requirements and Installation
First, you will need to set up the environment and extract pretraining weight of each video.
We offer an environment suitable for both VGCM and all VLLMs:
```bash
conda create -n mecd python=3.10
conda activate mecd
pip install -r requirements.txt
```
The pre-training weight of VGCM is available in [Google Drive](https://drive.google.com/file/d/1FScQim-nPgpr-SYRPIzVd5Dg6YYJbwQ1/view?usp=sharing).
## ✏️ Citation
```bash
@article{chen2024mecd,
title={MECD: Unlocking multi-event causal discovery in video reasoning},
author={Chen, Tieyuan and Liu, Huabin and He, Tianyao and Chen, Yihang and Ma, Xiao and Zhong, Cheng and Zhang, Yang and Wang, Yingxue and Lin, Hui and Lin, Weiyao and others},
journal={Advances in Neural Information Processing Systems},
volume={37},
pages={92554--92580},
year={2024}
}
@article{chen2025mecd+,
title={MECD+: Unlocking Event-Level Causal Graph Discovery for Video Reasoning},
author={Chen, Tieyuan and Liu, Huabin and Wang, Yi and Chen, Yihang and He, Tianyao and Gan, Chaofan and He, Huanyu and Lin, Weiyao},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year={2025}
}
```
### 👍 Acknowledgement
We would also like to recognize and commend the following open source projects, thank you for your great contribution to the open source community:
[VAR](https://github.com/leonnnop/VAR), [Video-LLaVA](https://github.com/PKU-YuanGroup/Video-LLaVA), [VideoChat2](https://github.com/OpenGVLab/Ask-Anything)
We would like to express our sincere gratitude to the PCs, SACs, ACs, as well as Reviewers 17Ce, 2Vef, eXFX, and 9my4, for their constructive feedback and support provided during the review process of NeurIPS 2024. Their insightful comments have been instrumental in enhancing the quality of our work.
We would also like to express our sincere gratitude to the TPAMI Associate Editor of MECD+, Reviewer 1-3 of MECD+, for their constructive suggestions and recognition during the review process of MECD+.
### ⏳ Ongoing
We will continue to update the performance of new state-of-the-art (SOTA) models on the MECD (MECD+) dataset,
and we will also continuously expand the volume of data and video sources in MECD (MECD+).